


AI ┐Ų╝╝įušō░┤Ż║12 į┬ 27 ╚š AI ┐Ų╝╝įušō╚źŪÕ╚A▓õ┴╦ę╗éĆčąėæĢ■Ż¼ų„Ņ}╩ŪĪĖÅ─░óĀ¢Ę© Go ĄĮ═©ė├╚╦╣żųŪ─▄Ż║─X┐ŲīW┼c╚╦╣żųŪ─▄Ī╣ĪŻ
▀@╩ŪŪÕ╚A┤¾īW─X┼cųŪ─▄īŹ“×╩ęūį 12 į┬ 15 ╚š│╔┴óų«║¾┼e▐kĄ─╩ū┤╬īWągčąėæĢ■ĪŻ
į┌▀@┤╬čąėæĢ■╔ŽŻ¼AI ┐Ų╝╝įušōĄ┌ę╗┤╬┐┤ĄĮ▀@├┤ČÓ─X┐ŲīW╝ęųvį§├┤ė├└Ž╩¾Īó║’ūėū÷īŹ“×ĪŻ│²┤╦ų«═ŌŻ¼AI ┐Ų╝╝įušōę▓┬ĀĄĮā╔ł÷ĘŪ│Żę²╚╦╔Ņ╦╝Ą─ AI ŽÓĻPł¾ĖµĪ¬Ī¬ę╗ł÷×ķÅłŌōį║╩┐ū÷Ą─ĪČ AI ║═╔±Įø┐ŲīWĪĘŻ¼┴Ēę╗ł÷╩ŪĮ±╚šŅ^Śl AI Lab ų„╚╬└Ņ║Į▓®╩┐Ą─ĪČ NLP ¼FĀŅ║═╬┤üĒĪĘĪŻ
┬Ā═Ļų«║¾ AI ┐Ų╝╝įušō╔ŅėX▀z║ČŻ¼×ķ╩▓├┤─žŻ┐ę“×ķÅłŌōį║╩┐║═└Ņ║Į▓®╩┐Ą─ł¾ĖµĘŪ│ŻųĄĄ├ AI 蹊┐╚╦åT╝Ü╝ÜŲĘ╬ČŻ¼Ą½į┌ł÷Ą─╚╦▓ó▓╗╩Ū║▄ČÓŻ¼ŪęČÓöĄ▓ó▓╗╩ŪĪĖAIerĪ╣ĪŻ
╗žüĒ║¾ AI ┐Ų╝╝įušōøQČ©Ė∙ō■¼Fł÷┼─Ą─ę╗ą®ššŲ¼║═ū÷Ą─ę╗ą®╣Pėø║åå╬▀ĆįŁę╗Ž┬ÅłŌōį║╩┐Ą─ł¾Ėµ¼Fł÷Ż©ø]─▄═Ļš¹ėøõø└Ņ║Į▓®╩┐Ą─ł¾ĖµŻ¼sadŻĪŻ®Ż¼┴─ĮŌ▀z║ČĪŻ
ÅłŌōį║╩┐Ą─ł¾Ėµ╚½│╠ėó╬─Ż¼Ą½ūŅ║¾ė├ųą╬─ū÷┴╦³cŠ”ų«╣PĪŻ
ÅłŌōį║╩┐į┌ł¾Ėµųą╩ūŽ╚Ęų╬÷┴╦╩▓├┤╩ŪųŪ─▄ĪŻ╦¹šJ×ķųŪ─▄░³║¼╚²éĆ│╔ĘųŻ║perceiveĪórational thinking ║═ taking actionĪŻŠC║ŽüĒšfŠ═╩ŪŻ¼ę╗éĆųŪ─▄¾wę¬─▄ē“Ėąų¬╦³ų▄ć·Ą─ŁhŠ│Ż¼▀Mąą╦╝┐╝▓ó▓╔╚ĪąąäėüĒūŅ┤¾╗»╦³īŹ¼F─│ą®─┐Ą─Ą─ÖCĢ■ĪŻ
¼Fį┌Ą─ AI model ¤o═Ō║§ā╔ĘNŅÉą═Ż║Ę¹╠¢─Żą═Ż©Symbolic modelŻ®║═üåĘ¹╠¢─Żą═Ż©Sub-symbolic modelŻ®╗“š▀ĘQ×ķ▀BĮėų„┴xŻ©ConnectionismŻ®ĪŻ
Ę¹╠¢─Żą═
Ę¹╠¢─Żą═Ą─╗∙▒Š╦╝Žļų„ę¬ė╔ J. McCarthy Ą╚╚╦ė┌ 1955 ─Ļ╠ß│÷ĪŻ╦¹éāšJ×ķ AI Ą─蹊┐╗∙ė┌▀@śėę╗éĆ▓┬ŽļŻ¼╝┤īW┴Ģ╗“š▀╚╬║╬Ųõ╦¹Ą─ųŪ─▄╠žš„įŁät╔ŽČ╝┐╔ęį▒╗Š½┤_Ąž├Ķ╩÷ĪŻ╦¹éā╠ß│÷ā╔éĆ╗∙▒Š╝┘įOŻ║
Ī±╬’└ĒĘ¹╠¢ŽĄĮy╝┘įOŻ║╬’└ĒĘ¹╠¢ŽĄĮy╩ŪųŪ─▄Ą─│õĘų▒žę¬Śl╝■Ż╗
Ī±╚╦─X║═ėŗ╦ŃÖCČ╝╩Ū╬’└ĒĘ¹╠¢ŽĄĮyŻ¼šJų¬▀^│╠Š═╩Ūį┌Ę¹╠¢▒Ē╩Š╔ŽĄ─▀\╦ŃĪŻ
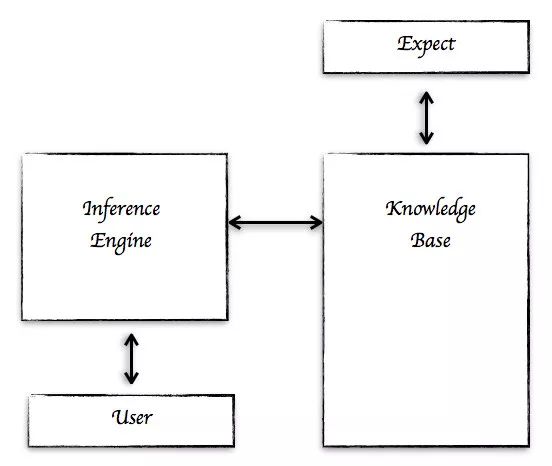
į┌ 1976 ─Ļ Newell ║═ Simon ╠ß│÷┴╦ę╗éĆĘ¹╠¢─Żą═ĪŻ╦³░³║¼ā╔▓┐ĘųŻ║ų¬ūRÄņ║══Ų└ĒÖCŻ©Inference EngineŻ®ĪŻ▀@ĘN AI ų„ę¬╩Ūų¬ūR“īäė╗“š▀╗∙ė┌ęÄätĄ──Żą═ĪŻ
į┌ McCarthy Ą╚╚╦╠ß│÷Ę¹╠¢─Żą═ų«║¾┤¾╝s 40 ─ĻŻ¼1997 ─Ļ IBM ═Ų│÷Ą─╗∙ė┌Ę¹╠¢─Żą═Ą─ IBM ╔Ņ╦{Ż©Deep BlueŻ®į┌ć°ļHŽ¾ŲÕ▒╚┘Éųąęį2 ┌A 1 öĪ 3 ŲĮ┤“öĪ┴╦«öĢrĄ─╩└Įń╣┌▄Ŗ KaspanovĪŻį┌╔Ņ╦{Ą─ŽĄĮyųąŻ¼░³║¼┴╦ 700,000 Ę▌╚╦ŅÉ┤¾Ä¤Ą─ŲÕūVŻ¼▀@ą®ŲÕūVĘųäeė├ V-value ║»öĄüĒ▒Ē╩ŠŻ¼║»öĄėą 8000 ČÓéĆūā┴┐ĪŻ
2011 ─ĻŻ¼IBM ╬ų╔Łį┌ŠC╦ć╣Ø─┐ĪČ╬ŻļU▀ģŠēĪĘųą┤“öĪ┴╦ūŅĖ▀¬äĮĄ├ų„▓╝└ŁĄ┬Īż¶ö╠žĀ¢║═▀Bä┘╝oõø▒Ż│ųš▀┐ŽĪżš▓īÄ╦╣ĪŻ═¼śė╦³ę▓╩Ū╗∙ė┌ų¬ūRĄ─Ę¹╠¢ą═ AI ŽĄĮyŻ¼╦³Ą─ų¬ūRüĒį┤ė┌░┘┐Ų╚½Ģ°ĪóūųĄõ Īóį~ĄõĪóą┬┬äĪó╬─īWū„ŲĘęį╝░ŠS╗∙░┘┐ŲĄ─╚½▓┐╬─▒ŠŻ¼į┌Ųõ 4TB Ą─┤┼▒Pųą░³║¼┴╦ 2 ā|ĒōĮYśŗ╗»║═ĘŪĮYśŗ╗»Ą─ą┼ŽóĪŻ
ęįWatson×ķ┤·▒ĒĄ─ą┬ę╗┤·Ą─╗∙ė┌ų¬ūRĄ─Ę¹╠¢─Żą═ŽĄĮyŽÓī”ų«Ū░ėą╔┘įSūā╗»ĪŻŲõę╗╩Ūų¬ūRÄņųąĄ─ų¬ūR▒Ē╩Šūā│╔ČÓśė╗»Ż╗ŲõČ■╩ŪČÓ═Ų└ĒÖCŻ©Multi-Inference EnginesŻ®ĮYśŗŻ╗Ųõ╚²╩Ūį÷╝ė┴╦┤¾▒Ŗų¬ūRŻ©üĒūį╗ź┬ōŠWŻ®ĪŻ

Ą½╩Ū▀@ĘNų¬ūR“īäėĄ─Ę¹╠¢─Żą═ę▓ėąŲõŠųŽ▐ų«╠ÄŻ¼╚ńŽ┬Ż║
Ī±ėą║▄ČÓ╚╦ŅÉąą×ķŻ©ų¬ūRŻ®▓ó▓╗─▄Š½┤_├Ķ╩÷Ż¼└²╚ń│ŻūRŻ╗
Ī±ų¬ūRÄņ┐é╩ŪėąŽ▐Ą─Ż¼╦³▓╗─▄░³║¼╦∙ėąĄ─ą┼ŽóŻ╗
Ī±ų¬ūR╩Ū┤_Č©Ą─Ż╗
Ī±╦³ų╗─▄├Ķ╩÷╠žČ©Ą─ŅIė“Ż╗
Ī±┤¾┴┐ų¬ūR▓╗─▄ū÷ĄĮČ©┴┐╗»Ż©└²╚ń┘|┴┐Ż®ĪŻ
╦∙ęį▀@ĘN─Żą═ų╗─▄į┌║Ļė^īė├µ╔Žė├üĒ─ŻöM╚╦ŅÉĄ──│ą®ąą×ķĪŻ
üåĘ¹╠¢─Żą═/▀BĮėų„┴x
1965 ─ĻŻ¼į┌▀_╠ž├®╦╣Ž─╝ŠčąėæĢ■Ą─╠ßūh╬─╝■Ż©http://t.cn/RAnjsCFŻ®Ą─å¢Ņ} 2 ųąšfĄĮĪĖį§├┤░▓┼┼ę╗ĮMŻ©╝┘įOĄ─Ż®╔±Įøį¬üĒą╬│╔Ė┼─ŅŻ┐ĪŁĪŁ▀@éĆå¢Ņ}╚įąĶę¬Ė³ČÓĄ─└Ēšō╣żū„ĪŻĪ╣
ī”ė┌╔±ĮøŠWĮjŻ¼┤¾ų┬ėąā╔éĆĢrŲ┌ĪŻĄ┌ę╗éĆ×ķ£\īė╔±ĮøŠWĮjŻ©Shallow Neural NetworkŻ®Ż¼▀@éĆŠWĮjų╗ėąę╗īėļ[▓žīėĪŻį┌▀@ĘNŠWĮjųąŻ¼ąĶę¬╩ų╣ż╠žš„Ż©Hand-crafted FeaturesŻ®üĒśŗĮ©ĘųŅÉŲ„Ż¼ę“┤╦╦³ąĶę¬ėąŅIė“Ą─ų¬ūRĪŻ
┴Ē═Ōę╗ĘN╩Ūį┌ 2000-2006 ─ĻķgŻ¼ė╔ Igor Aizenberg ║═ Geoff Hinton ═Ļ│╔ĪŻ▀@éĆŠWĮjėąĖ³ČÓĄ─ļ[▓žīėŻ¼ĘQ×ķČÓļ[▓žīėŻ©╔ŅČ╚Ż®╔±ĮøŠWĮjĪŻČÓļ[▓žīėĄ─ĮYśŗĦüĒ┴╦║▄┤¾Ą─ūā╗»ĪŻ╩ūŽ╚╩ŪŻ¼╬ęéā┐╔ęįė├ Raw data ┤·╠µ╩ų╣ż╠žš„Ż¼╦∙ęįŅIė“ų¬ūRę▓Š═▓╗į┘╩Ū▒žĒÜĄ─┴╦ĪŻęįłDŽ±×ķ└²Ż¼╬ęéāų╗ąĶę¬īółDŽ±░┤šš pixel Ą─Ė±╩Į▌ö╚ļ╝┤┐╔ĪŻŲõ┤╬Ż¼╔ŅČ╚╔±ĮøŠWĮjūīüåĘ¹╠¢─Żą═Ą─▒Ē¼Fėą┴╦║▄┤¾Ą─╠ßĖ▀ĪŻį┘┤╬Ż¼į┌ 90 ─Ļ┤· AI 蹊┐╚╦åT░lš╣┴╦ę╗ŽĄ┴ą│╔╩ņĄ─ĮyėŗöĄīW╣żŠ▀Ż¼▀@į┌─Żą═ųąėą║▄ČÓ▒Ē¼FŻ¼ūī─Żą═ūāĄ├Ė³Š▀┐╔Č╚┴┐║═┐╔“×ūCąįĪŻ┴Ē═ŌŻ¼▀@éĆ─Żą═ėą║▄ŪÕ╬·Ą─╔±Įø┐ŲīWĄ─ĮŌßīĪŻ
▀@ĘN AI ŽĄĮyų„ę¬╩Ū╗∙ė┌öĄō■“īäėĪŻų╗ę¬ėąöĄō■Ż¼╬ęéā▓╗ąĶę¬ėą╠½ČÓĄ─ŅIė“ų¬ūRŠ═┐╔ęįį┌╚╬äšųąū÷Ą├║▄║├ĪŻ╗∙ė┌╔ŅČ╚╔±ĮøŠWĮjĄ─└²ūė║▄ČÓŻ¼└²╚ń AlphaGoĪŻ
ŽÓ▒╚ė┌╚╦ŅÉĄ─╔±ĮøŠWĮjŻ¼╦³╚įėąę╗ŽĄ┴ąĄ─╚▒³cĪŻ╚ńŽ┬Ż║

ęį 2014 ─Ļ Goodfellow ░l▒ĒĄ─ĪČAdversarial examples and adversarial trainingĪĘ×ķ└²Ż¼▌ö╚ļĄ─łDŲ¼╝ė╔Žę╗³c³cĄ─įļ┬ĢŻ¼AI ŽĄĮyŠ═īóę╗Åł├„’@╩Ūą▄žłĄ─łDŲ¼ęį 99.3% Ą─ų├ą┼Č╚ūRäe│╔ķL▒█į│ĪŻ╦∙ęį─┐Ū░Ą─ AI ŽĄĮyį┌ robustness ╔Ž▀Ć╩ŪĘŪ│Ż╚§Ą─ĪŻ

▀@ĘN AI ŽĄĮyų╗╩Ūę╗ĘNĘųŅÉÖCŲ„Ż¼╩Ūę╗éĆ AI without UnderstandingŻ¼╦∙ęįāHāHę└┐┐╗∙ė┌öĄō■“īäėĄ─╔ŅČ╚īW┴Ģ║▄ļy«a╔·šµš²Ą─ųŪ─▄Ż¼ę▓▀hø]ėąė|╝░ųŪ─▄Ą─║╦ą─ĪŻ╚¶Žļū÷ĄĮšµš²Ą─ųŪ─▄Ż¼Š═▒žĒÜ

╚╦╣żųŪ─▄Ą─║╦ą─
Ū░├µšfĄ└Ż¼╔ŅČ╚īW┴Ģ▓óø]ėąė|╝░ĄĮ╚╦╣żųŪ─▄Ą─║╦ą─Ż¼─Ū├┤╚╦╣żųŪ─▄Ą─║╦ą─╩Ū╩▓├┤─žŻ┐ÅłŌōį║╩┐šJ×ķų„ę¬▒Ē¼F×ķęįŽ┬╬ÕéĆĘĮ├µŻ║
Ī±į┌╚▒Ę”ų¬ūR║═öĄō■Ą─ŪķørŽ┬ę└╚╗─▄ē“═Ļ│╔╚╬䚯╗
Ī±į┌ą┼Žó▓╗═Ļ╔ŲŻ©╔§ų┴╚▒Ę”ą┼ŽóŻ®Ą─ŪķørŽ┬ę└╚╗─▄ē“═Ļ│╔╚╬䚯╗
Ī±─▄ē“╠Ä└ĒĘŪ┤_Č©ąįĄ─╚╬䚯╗
Ī±─▄ē“╠Ä└ĒäėæB╚╬䚯╗
Ī±─▄ē“╠Ä└ĒČÓŅIė“║═ČÓ╚╬äšĪŻ
AI 蹊┐Ą─ą┬┌ģä▌
╗∙ė┌ī”╔Ž├µĄ─ėæšōŻ¼┐╔ęį┐┤│÷─┐Ū░ AI Ą─蹊┐ėąā╔ĘNŻ¼╗∙ė┌ų¬ūRĄ─Ę¹╠¢─Żą═║═╗∙ė┌öĄō■Ą─üåĘ¹╠¢─Żą═Ż©▀BĮėų„┴xŻ®ĪŻÅłŌōį║╩┐šJ×ķ¼Fį┌į┌ AI 蹊┐ųąØuØu│÷¼F┴╦ę╗ĘNą┬Ą─┌ģä▌Ż¼╝┤Į©┴óę╗ĘN═¼Ģr╗∙ė┌ų¬ūR║═öĄō■Ą─ AI ŽĄĮyĪŻ
╦¹šJ×ķŻ¼╠Ä└Ēų¬ūR╩Ū╚╦ŅÉ╦∙╔├ķLĄ─Ż¼Č°╠Ä└ĒöĄō■╩Ūėŗ╦ŃÖC╦∙╔├ķLĄ─ĪŻ╚ń╣¹─▄ē“īóČ■š▀ĮY║ŽŲüĒŻ¼ę╗Č©─▄ē“śŗĮ©│÷ę╗éĆ▒╚╚╦ŅÉĖ³╝ėųŪ─▄Ą─ŽĄĮyĪŻ
╚ń║╬╚źū÷─žŻ┐
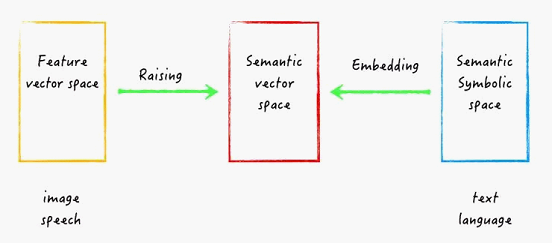
¼Fį┌╬ęéāėąā╔ĘN╗∙▒ŠĄ─ AI ĘĮĘ©ĪŻę╗ĘN╩Ū╗∙ė┌šZ┴xĘ¹╠¢Ą─ĘĮĘ©Ż¼ę╗░Ńė├į┌╠Ä└Ē╬─▒Š║═šZčįŻ¼╬ęéāĢ■śŗĮ©ę╗éĆšZ┴xĘ¹╠¢┐šķgŻ©Semantic Symbolic SpaceŻ®ĪŻ┴Ēę╗ĘN╩Ū╗∙ė┌öĄō■Ą─╠žąįŽ“┴┐Ą─ĘĮĘ©Ż¼ė├üĒ╠Ä└ĒłDŽ±║═šZ궯¼╬ęéāĢ■śŗĮ©ę╗éĆ╠žąįŽ“┴┐┐šķgŻ©Feature Vector SpaceŻ®ĪŻ
ę“┤╦╬ęéā┐╔ęįśŗĮ©ę╗éĆą┬Ą─┐šķgŻ¼Įąū÷šZ┴xŽ“┴┐┐šķgŻ©Semantic Vector SpaceŻ®Ż¼╝┤īóšZ┴xĘ¹╠¢┐šķg▀Mąą embedding ╠Ä└Ē╗“š▀īó╠žąįŽ“┴┐┐šķg▀Mąą Raising ╠Ä└ĒĪŻ═©▀^▀@ĘNĘĮĘ©Ż¼╬ęéāīó┐╔ęįĮyę╗╠Ä└Ē textĪólanguageĪóimage ║═ speechĪŻ
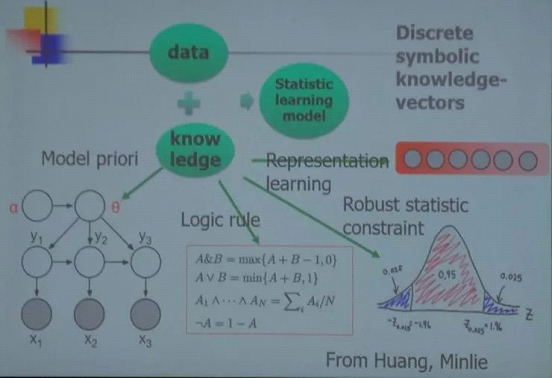
ÅłŌōį║╩┐šJ×ķį┌▀@ą®ĘĮ├µŻ¼ė╚Ųõ╩Ūį┌īó╠žąįŽ“┴┐┐šķg raising ĄĮšZ┴x┐šķg╔ŽŻ¼╬ęéāæ¬įōŽ“╔±Įø┐ŲīWīW┴ĢĪŻ└²╚ń─X╔±Įøųąėą feedback connectionĪólateral connectionsĪósparse firingĪóattention mechanismĪómulti-modelĪómemory Ą╚ÖCųŲŻ¼▀@ą®Č╝ųĄĄ├įOėŗ AI ŽĄĮyĄ─╚╦åT╚źūóęŌ║═īW┴ĢĪŻ
蹊┐░Ė└²
ÅłŌōį║╩┐ĮķĮB┴╦╦─éĆ░Ė└²üĒšf├„╚ń║╬Ž“╔±Įø┐ŲīWīW┴ĢŻ¼ęį╝░╚ń║╬śŗĮ©═¼Ģr╗∙ė┌ų¬ūR║═öĄō■Ą─ AI ŽĄĮyĪŻŻ©╣½▒Ŗ╠¢║¾┼_░l╦═ĪĖÅłŌōĪ╣Ż¼½@╚Ī╦─Ų¬░Ė└²šō╬─įŁ╬─Ż®
ę╗ĪóSparse Firing + HMAX
šō╬─Ż║Sparsity-Regularized HMAX for Visual Recognition
▀@ĒŚ╣żū„Ą─ę╗éĆäōą┬³cį┌ė┌īó╔±Įø┐ŲīWųąĄ─░l¼F Sparse firing ║═ HMAX ĮY║Žį┌ę╗ŲĪŻ
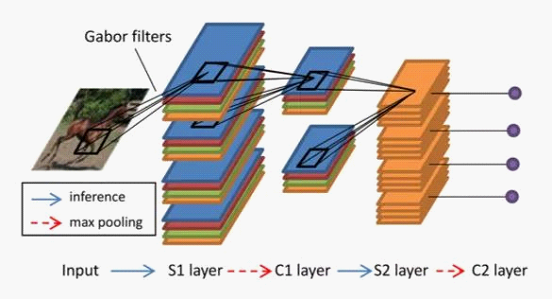
HMAX ─Żą═╩Ū Riesenhuber, M. & Poggio, T Ą╚╚╦ė┌ 1999 ─Ļ╠ß│÷Ż¼Ųõ└Ē─Ņ╩Ū─ŻĘ┬╚╦Ą─šJų¬Ż¼ė╔³cĄĮŠĆĄĮ├µų╝ē│ķŽ¾Ż¼▀ĆįŁĖ▀╝ē╠žąįĪŻHMAX ╩Ūėŗ╦ŃÖCęĢėXųąĘŪ│Żųžę¬Ą─ę╗éĆ─Żą═ĪŻ
Sparse firing ╩Ū╔±Įø┐ŲīWųąĄ─ę╗éĆĖ┼─ŅĪŻ╔±Įø┐ŲīWĄ─蹊┐▒Ē├„į┌╚╦Ą─┤¾─XųąŻ¼ßśī”ę╗éĆ┤╠╝ż┤¾ČÓöĄ╔±Įøį¬╩Ū│┴─¼Ą─ĪŻ└²╚ńę└šš┤¾─Xā╚╝Ü░¹Ą─├▄Č╚Īó╠Įßś┤¾ąĪęį╝░╠Įßś┐╔ęį£y┴┐ĄĮĄ─ą┼╠¢ŠÓļxüĒ╣└ėŗŻ¼ę╗Ė∙╠Įßśæ¬įō┐╔ęį£yĄĮų▄ć·╩«éĆ╔§ų┴╔Ž░┘éĆ╔±Įøį¬Ą─ą┼╠¢Ż¼Ą½īŹļHŪķør═©│Żų╗─▄£yĄĮÄūéĆ╔±Įøį¬ą┼╠¢Ż¼90% ęį╔ŽĄ─╔±Įøį¬╩Ū£y▓╗ĄĮĄ─ĪŻ▀@Š═╩Ūšfßśī”ę╗éĆ┤╠╝żŻ¼ų╗ėą╔┘öĄŻ©ŽĪ╩ĶŻ®╔±Įøį¬╩Ū▒╗╝ż╗ŅĄ─ĪŻ
┤¾─X╔±Įøį¬Ą─▀@ĘN sparse firing ╝ż╗ŅĘĮ╩ĮŻ¼╗“š▀šf sparse coding ĘĮ╩ĮėąįSČÓā׳cŻ¼ę╗ĘĮ├µ┐╔ęįė├╔┘┴┐Ą─╔±Įøį¬ī”┤¾┴┐Ą─╠žš„▀MąąŠÄ┤aŻ¼┴Ēę╗ĘĮ├µę▓─▄ĮĄĄ═ĮŌ┤aš`┼ąęį╝░─▄┴┐ōp║─Ą╚Ą╚ĪŻ
▀@Ų¬╬─š┬Ą─╣żū„š²╩Ūīó Sparse firing ┼c HMAX ─Żą═ŽÓĮY║ŽŻ¼æ¬ė├ė┌łDŽ±ūRäe╚╬äš«öųąĪŻ╣żū„ĘŪ│ŻėąęŌ╦╝Ż¼Ėą┼d╚żĄ─ūxš▀▓╗Ę┴ę╗ūxĪŻ
Č■ĪóęĢėXūRäe“×ūC┤a
šō╬─Ż║A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs ( Science, 26 Oct. 2017)
▀@Ų¬╬─š┬ė┌Į±─Ļ 10 į┬Ę▌░l▒Ēė┌ĪČScienceĪĘŲ┌┐»Ż¼╩Ū╚╦╣żųŪ─▄Ž“╔±Įø┐ŲīWīW┴ĢĄ─ę╗éĆĘČ└²ĪŻ
─┐Ū░Ą─ÖCŲ„īW┴Ģ─Żą═į┌łDŽ±ūRäeĄ─╚╬äšųą═∙═∙ąĶę¬┤¾┴┐Ą─ė¢ŠÜöĄō■╝»Ż¼Č°ė¢ŠÜĄ─ĮY╣¹═∙═∙ų╗─▄æ¬ė├ė┌╠žČ©Ą─ŅIė“ā╚ĪŻĄ½╚╦ŅÉĄ─ęĢėXųŪ─▄ät┐╔ęį═©▀^╔┘öĄśė▒ŠŻ©╔§ų┴▓╗ąĶ꬜ė▒ŠŻ®üĒīW┴Ģ▓ó─▄ē“║▄▌pęūĄž▀węŲĄĮ═Ļ╚½▓╗═¼Ą─ŪķŠ░«öųąĪŻ╦∙ęįŽ“╚╦ŅÉĄ─ęĢėX╔±ĮøÖC└ĒīW┴Ģ╗“įS╩ŪÖCŲ„īW┴Ģ─Żą═▀Mę╗▓Į░lš╣Ą─ĘĮŽ“ĪŻ
į┌▀@Ų¬╬─š┬ųąŻ¼ų¬├¹Ą─╚╦╣żųŪ─▄äōśI╣½╦Š Vicarious Š══©▀^╚╦ŅÉęĢėXę╗ą®╣żū„ÖC└ĒĄ─åó░lŻ¼śŗĮ©┴╦ę╗éĆīė╝ē─Żą═Ż¼╦¹éāĘQų«×ķĪĖ▀fÜwŲżīėŠWĮjĪ╣Ż©Recursive Cortical Network, RCNŻ®ĪŻį┌─Żą═ųą╦¹éāę²╚ļ┴╦ęĢėXĖ┼┬╩╔·│╔Ą──Żą═┐“╝▄Ż¼Ųõųą╗∙ė┌Ž¹Žóé„╦═Ż©message-passingŻ®Ą─═ŲöÓŻ¼ęįĮyę╗Ą─ĘĮ╩Į╠Ä└ĒłDŽ±Ą─ūRäeĪóĘųĖŅ║══Ų└ĒŻ©ReasoningŻ®ĪŻ
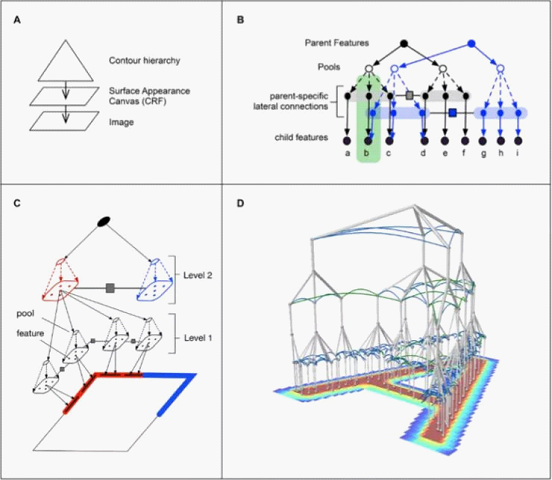
▀@éĆĘĮĘ©▒Ē¼F│÷┴╦ĘŪ│Żā׹ѥ─Ę║╗»║═š┌ō§═Ų└ĒŻ©occlusion-reasoningŻ®─▄┴”Ż¼į┌└¦ļyĄ─ł÷Š░╬─ūųūRäe╚╬äš╔Ž▀hā×ė┌╔ŅČ╚╔±ĮøŠWĮjŻ¼ŪęŠ▀ėą 300 ▒ČĄ─öĄō■ą¦┬╩Ż©data efficientŻ®ā×ä▌ĪŻ
ŲõīŹ“×ĮY╣¹╚ńŽ┬▒Ē
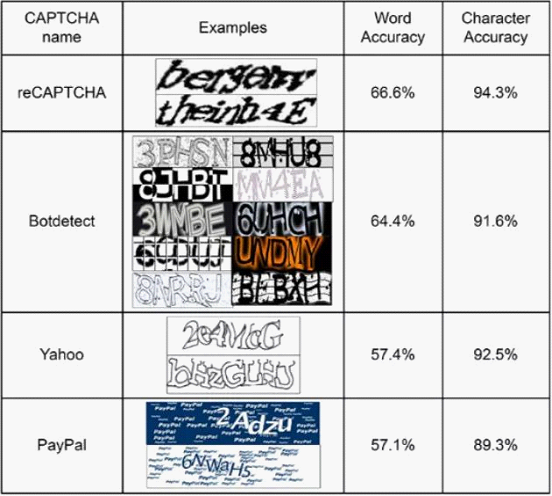
į┌ reCAPTCHA Ą─“×ūC┤aå╬į~ūRäe£╩┤_┬╩ęčĮø┐╔ęį▀_ĄĮ 66.6%Ż¼BotDetect ×ķ 64.4%Ż¼č┼╗ó╔Ž×ķ 57.4%Ż¼PayPal ╔Ž×ķ 57.1%ĪŻ
╚²ĪóDNN Ą─┐╔ĮŌßīąį
šō╬─Ż║Improving interpretability of deep neural networks with semantic information (2017)
▀@Ų¬╬─š┬╩ŪÅłŌōį║╩┐ĮMį┌ CVPR 2017 ╔ŽĄ─ę╗Ų¬šō╬─Ż¼╩ŪĪĖKnowledge+dataĪ╣Ą─ę╗éĆĄõą═ĘČ└²ĪŻ
į┌é„ĮyĄ─łDŽ±ūRäeĄ─ DNN ─Żą═ųąŻ¼╬ęéā▌ö╚ļłDŲ¼Ż¼Ą├ĄĮ├Ķ╩÷ąįĮY╣¹Ż¼Ą½╩Ū╬ęéāģs▓╗ų¬Ą└×ķ╩▓├┤Ģ■Ą├ĄĮ▀@śėĄ─ĮY╣¹Ż¼ę▓▓╗ų¬Ą└ļ[▓žīėųąČ╝╩Ū╩▓├┤ featureŻ¼╗“š▀«öĄ├ĄĮę╗éĆÕeš`ĮY╣¹Ģr╬ęéā▓╗ų¬Ą└×ķ╩▓├┤Ģ■ÕeĪŻ
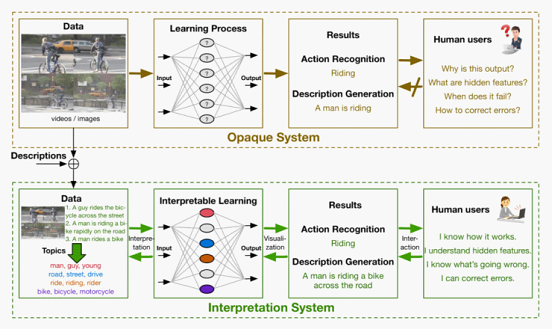
▀@Ų¬╬─š┬Ą─蹊┐ų„ę¬ĘĮĘ©Š═╩ŪŽ╚½@Ą├ę╗ą®╚╦ŅÉī”łDŲ¼Ą─├Ķ╩÷ū„×ķšZ┴xą┼ŽóöĄō■Ż╗īó▀@ą®öĄō■║═łDŲ¼═¼Ģr╦═╚ļĄĮ DNN ─Żą═ųą▀Mąąė¢ŠÜŻ╗▀@└’├┐ę╗éĆ╔±Įøį¬Č╝Ģ■┼cę╗éĆ topic ▀MąąĻP┬ōŻ¼ė┌╩Ūš¹éĆŠWĮjūāĄ├Š▀ėą┐╔ĮŌßīąįĪŻ
╦─ĪóZero-shot ęĢŅlūRäe
šō╬─Ż║Recognizing an Action Using Its Name: A Knowledge-Based Approach
▀@Ų¬╬─š┬Ą─╣żū„ę▓╩Ūę╗éĆĄõą═Ą─ĪĖKnowledge+dataĪ╣ĘČ└²ĪŻ
¼FėąĄ─äėū„ūRäe╦ŃĘ©ąĶę¬ę╗ĮMš²├µĄ─╩Š└²üĒė¢ŠÜ├┐éĆäėū„Ą─ĘųŅÉŲ„ĪŻĄ½╩ŪŻ¼╬ęéāų¬Ą└Ż¼äėū„ŅÉĄ─öĄ┴┐ĘŪ│Ż┤¾Ż¼ė├æ¶Ą─▓ķįāūā╗»ę▓║▄┤¾ĪŻŅAŽ╚Č©┴x╦∙ėą┐╔─▄Ą─ąąäėŅÉäe╩Ū▓╗ŪąīŹļHĄ─ĪŻ
į┌▒Š╬─ųąū„š▀╠ß│÷┴╦ę╗ĘN▓╗ąĶ꬚²├µ╩Š└²Ą─ĘĮĘ©Ż¼═©│Ż▀@ĘNĘĮĘ©▒╗ĘQ×ķĪĖZero-shot LearningĪ╣ĪŻ─┐Ū░Ą─┴Ń³cīW┴Ģ─Ż╩Į═©│Żė¢ŠÜę╗ŽĄ┴ąī┘ąįĘųŅÉŲ„Ż¼╚╗║¾Ė∙ō■ī┘ąį▒Ē╩ŠūRäe─┐ś╦äėū„ĪŻ×ķ┴╦┤_▒Ż╠žČ©äėū„ŅÉäeĄ─ūŅ┤¾Ė▓╔wĘČć·Ż¼╗∙ė┌ī┘ąįĄ─ĘĮĘ©ąĶę¬┤¾┴┐┐╔┐┐Ūę£╩┤_Ą─ī┘ąįĘųŅÉŲ„Ż¼▀@į┌¼FīŹ╩└Įńųą═©│Ż╩Ū▓╗┐╔ė├Ą─ĪŻ
į┌▀@Ų¬šō╬─ųąŻ¼ū„š▀╠ß│÷Ą─ĘĮĘ©ų╗ąĶę¬ę╗éĆąąäė├¹ĘQū„×ķ▌ö╚ļüĒūRäeĖą┼d╚żĄ─ąą×ķŻ¼ø]ėą╚╬║╬ŅAŽ╚ė¢ŠÜĄ─ī┘ąįĘųŅÉŲ„║═š²├µĄ─╩Š└²ĪŻ

ĮoČ©ę╗éĆäėū„├¹ĘQ║¾Ż¼╩ūŽ╚Ė∙ō■═Ō▓┐ų¬ūRŻ©└²╚ń WikipediaŻ®Į©┴óę╗éĆŅÉ▒╚│žŻ¼ŅÉ▒╚│žųąĄ─├┐éĆäėū„Č╝Ģ■┼c▓╗═¼īė┤╬Ą──┐ś╦äėū„ėąĻPĪŻ
Å─═Ō▓┐ų¬ūR═ŲöÓĄ─ŽÓĻPąįą┼Žó┐╔─▄╩ŪÓąļsĄ─ĪŻ╦∙ęį╦¹éāėų╠ß│÷ę╗ĘN╦ŃĘ©Ż¼╝┤ūį▀mæ¬ČÓ─Żą═ų╚▒Ż│ųė│╔õŻ©Adaptive multi-model rank-preserving mapping model, AMRMŻ®üĒė¢ŠÜäėū„ūRäeĄ─ĘųŅÉŲ„Ż¼─▄ē“ūį▀mæ¬Ąžįu╣└ŅÉ▒╚│žųą├┐éĆłDŲ¼Ą─ŽÓĻPąįĪŻ
ęį╔Ž╦─éĆ└²ūėėąā╔ŅÉŻ¼ę╗ŅÉ╩ŪŽ“╔±Įø┐ŲīWīW┴ĢĄ─ĮY╣¹Ż╗ę╗ŅÉ╩Ū╗∙ė┌ĪĖöĄō■+ų¬ūRĪ╣Ą─ĮY╣¹ĪŻŻ©╣½▒Ŗ╠¢║¾┼_░l╦═ĪĖÅłŌōĪ╣Ż¼½@╚Ī╦─Ų¬░Ė└²šō╬─įŁ╬─Ż®
ÅłŌōį║╩┐ĮķĮBšf╦¹éā╣żū„Ą─ę╗éĆ╦╝┬ĘŠ═╩ŪŻ║öĄō■+ų¬ūR=ĮyėŗīW┴Ģ─Żą═ĪŻŲõųąų¬ūR░³└©Ž╚“×─Żą═Īó▀ē▌ŗęÄätĪó▒Ē╩ŠīW┴ĢĪóÅŖĮĪĄ─Įyėŗ╝s╩°Ą╚ĪŻ
┤╦═Ō╦¹▀Ć╠ߥĮ┴╦Ą─ Bayesian Deep Learning Ą─Ė┼─ŅĪŻ

ūŅ║¾╦¹šJ×ķ╬ęéā─┐Ū░Ą─ AI ŽĄĮy╩Ūį┌Įķė^īė├µ╔Ž─ŻĘ┬┴╦╚╦ŅÉŻ¼╬ęéā▀ĆąĶꬎ“╔±Įø┐ŲīWīW┴Ģ║═║Žū„ĪŻį┌ AI ŽĄĮyĄ─蹊┐ųąæ¬«öīóų¬ūR“īäė║═öĄō■“īäėĮY║ŽŲüĒŻ¼īó└Ēąįąą×ķ║═Ėąąįąą×ķĮY║ŽŲüĒĪŻ
┐éĮYŻ©äØųž³cŻ®
ÅłŌōį║╩┐č▌ųvĄ─┴┴³cį┌ūŅ║¾Ą─ summaryŻ¼įŁ╬─š¹└Ē╚ńŽ┬Ż©╔įū„ą▐Ė─Ż®Ż║

¶öčĖšfĄĮŻ¼▓╗═¼Ą─╚╦ī”ĪČ╝tśŪē¶ĪĘėą▓╗═¼Ą─┐┤Ę©Ż¼ĮøØ·īW╝ę┐┤ĄĮĪČęūĪĘŻ¼Ą└īW╝ę┐┤ĄĮę∙Ż¼▓┼ūė┐┤ĄĮ└pŠdŻ¼Ė’├³╝ę┐┤ĄĮĘ┤ØMŻ¼┴„čį╝ę┐┤ĄĮīmķØ├ž╩┬ĪŻ
¼Fį┌Ą─╚╦╣żųŪ─▄ėą³cā║Ž±ĪČ╝tśŪē¶ĪĘŻ¼▓╗═¼Ą─╚╦ėą▓╗═¼Ą─┐┤Ę©ĪŻŲ¾śI╝ę┐┤ĄĮ╔╠ÖCŻ¼┐ŲīW╝ꯩ╗¶ĮŻ®┐┤ĄĮ╬ŻļUŻ¼╣ż│╠Ĥ┐┤ĄĮæ¬ė├Ū░Š░Ż¼└Ž░┘ąš┐┤ĄĮ AlphaGo ┤“öĪ└Ņ╩└╩»ĪŻ╬ę¼Fį┌Š═šfĮ╠╩┌éāæ¬įō┐┤ĄĮ╩▓├┤Ż¼▀@ę▓╩Ū╬ęĮ±╠ņł¾ĖµŽŻ═¹┤¾╝ę─▄ē“┐┤ĄĮĄ─ĪŻ
┐┤ĄĮ╩▓├┤─žŻ┐Š═╩ŪĪ¬Ī¬AI ┐ŲīWĄ─╩’╣ŌĪŻ
┤¾╝ę┐┤┤² AIŻ¼ėąā╔éĆ▀^│╠ĪŻ▀^╚ź╩ŪĄ═┐┤┴╦ AIŻ¼ėXĄ├ AI ø]╩▓├┤ĪŻ¼Fį┌ AlphaGo │÷üĒęį║¾Ż¼═╗╚╗ AI ╔Ž╠ņ┴╦Ż¼┤¾╝ęī”╦³č÷ęĢ┴╦ĪŻ╬ęĖµįV┤¾╝ęŻ¼▀@ā╔éĆČ╝▓╗ī”ĪŻ┤¾╝ęę¬ŲĮęĢ AIĪŻ
×ķ╩▓├┤▀^╚źī” AI ėą▀@éĆėĪŽ¾─žŻ┐┤_īŹŻ¼▀^╚źĄ─ AI ╬ęéāø]ėą┘YĖ±╚źšäŻ¼ę“×ķ╬ęéāų╗ėą▓┬£yĪó╝┘įOŻ¼ų╗ėą case by caseĪŻ╬ęéāø]ėą╩▓├┤▒Š╩┬ĪŻį┘╝ė╔Žėąą®╚╦│┤ū„Ż¼▓╗┐┐ūVĄ─¢|╬„║▄ČÓĪŻ╦∙ęį▀^╚ź╬ęéā▓╗─▄Įo┤¾╝ęšäĪŻ
¼Fį┌╬ęéāėąŽŻ═¹Įo┤¾╝ęšäĄ─Ż¼Š═╩Ūäé▓┼ųvĄ─ĪŻ¼Fį┌Å─╔ŅČ╚īW┴Ģųą┤¾╝ę┐┤ĄĮĄ─╩ŪÅVĘ║Ą─æ¬ė├ĪŻĄ½╩Ūø]ėą┐┤ĄĮ╔ŅČ╚īW┴ĢĮo╬ęéā³c╚╝┴╦ę╗éĆ╩’╣ŌŻ¼Š═╩Ū╚╦╣żųŪ─▄═Ļ╚½┐╔ęįė├Į©┴óöĄīW─Żą═Ą─ĘĮĘ©üĒū÷ĪŻ«ö╚╗╦³ę▓ĖµįV╬ęéāŻ¼╣Ōė├öĄīWĄ─ĘĮĘ©üĒĮ©įņ╚╦╣żųŪ─▄╩Ū▓╗ąąĄ─Ż¼└²╚ń╔ŅČ╚īW┴Ģ½@Ą├Ą─ĮY╣¹ų╗╩Ūę╗éĆÖCąĄĄ─ĘųŅÉŲ„Ż¼▀@Ė·╚╦Ą─šJų¬╗“Ėąų¬═Ļ╚½╩Ūā╔┤a╩┬ĪŻ
─Ū├┤╬ęéāĮėŽ┬üĒį§├┤ū▀Ž“Į©įņ╚╦╣żųŪ─▄Ą─öĄīW─Żą═▀@ę╗▓Į─žŻ┐ų╗ėąā╔Śl┬ĘĪŻę╗ŚlŠ═╩ŪŽ“─X┐ŲīWīW┴ĢŻ¼┐┤┤¾─X└’├µ╩Ūį§├┤ū÷ĄĮųŪ─▄Ą─ĪŻ┤¾─X└’├µę▓╩Ū╩╣ė├╔±ĮøŠWĮjŻ¼ ×ķ╩▓├┤╦³┐╔ęįšJūRĪĖ°BĪ╣Ż¼Č°ėŗ╦ŃÖCŠ═▓╗ąą─žŻ┐╬ęéā║▄ŪÕ│■Ż¼ėŗ╦ŃÖCĄ─▀@éĆ╔±ĮøŠWĮj║═┤¾─XĄ─╔±ĮøŠWĮj▓╗┐╔═¼╚šČ°šZĪŻ╬ęéā▒žĒÜŽ“┤¾─XīW┴ĢĪŻ
┴Ēę╗Śl┬ĘŠ═╩Ū░čų¬ūR║═öĄō■ĮY║ŽŲüĒĪŻ┤¾╝ęŽļę╗ŽļŻ¼╚╦Ą─ųŪ─▄ų„ę¬▓╗╩ŪüĒūįė┌öĄō■Ż¼Č°╩ŪüĒūįė┌ų¬ūRĪŻĄ½╩Ū×ķ╩▓├┤┤¾╝ęę¬░čöĄō■┐┤Ą├▀@├┤ųž─žŻ┐▀@╩Ūę“×ķöĄō■║▄ČÓŻ¼Č°Ūęėŗ╦ŃÖCūŅ╔├ķLĄ─Š═╩ŪöĄō■Ą─╠Ä└ĒĪŻ╦∙ęįŠ═Įo┤¾╝ęę╗éĆ─Ż║²Ą─šJūRŻ¼ęį×ķöĄō■øQČ©ę╗ŪąĪŻ▀@╩ŪÕeĄ─ĪŻĄ½╩Ū▀@ę▓Įo╬ęéā╠ß┴╦éĆŽŻ═¹Ż¼╝╚╚╗ėŗ╦ŃÖCĖŃöĄō■ģ¢║”Ż¼╚╦└¹ė├ų¬ūRģ¢║”Ż¼╚ń╣¹╬ęéā─▄ē“ūī▀@ā╔éĆĮY║ŽŲüĒŻ¼╬ęéāŠ═ėąŽŻ═¹ū÷│÷▒╚╚╦▀Ćę¬║├Ą─ŽĄĮyĪŻ
å¢Ż║Åł└ŽÄ¤─·║├ĪŻ─·ūŅ║¾ę╗éĆ slice šfį┌ AI ųą╔╠╚╦┐┤ĄĮ┴╦╔╠ÖCĄ╚Ą╚ĪŻ╦∙ęį╬ę╠žäeŽļų¬Ą└─·ūŅ║¾å¢Ą─å¢Ņ}Ą─┤░ĖŻ¼Į╠╩┌éāæ¬įō┐┤ĄĮĄ─╩▓├┤Ż┐
ÅłŌōŻ║Į╠╩┌欫ö┐┤ĄĮĄ─╩ŪĪ¬Ī¬╚źū÷╚╦╣żųŪ─▄Ą─╗∙ĄAå¢Ņ}ĪŻ╬ęéā▓╗─▄╚ź┐┤─ŪéĆ╔╠ÖCŻ¼╔╠ÖCæ¬įōūīŲ¾śI╝ę╚ź┐┤ĪŻ╬ę¼Fį┌šJ×ķ╚╦╣żųŪ─▄š²╠Äį┌═╗ŲŲĄ─Ū░ę╣ĪŻ╔ŅČ╚īW┴Ģ▓╗╩Ū╬ęéāĄ─═╗ŲŲŻ¼╔ŅČ╚īW┴Ģų╗╩Ūš╣╩Š┴╦═╗ŲŲĄ─ŽŻ═¹Ż¼ę“×ķ╔ŅČ╚īW┴Ģ▓óø]ėąśŗįņšµš²Ą─ IntelligenceĪŻ
¼Fį┌╬ęéāėąÖCĢ■ė|╝░ĄĮ the core of intelligenceĪŻį┌╩▓├┤ŪķørŽ┬╬ęéā▓┼ėą┐╔─▄ė|┼÷ the core of intelligence ─žŻ┐Š═╩Ūäé▓┼╬ęųv─Ū 5 éĆŚl╝■Ż¼╝┤
Ī±į┌╚▒Ę”ų¬ūR║═öĄō■Ą─ŪķørŽ┬ę└╚╗─▄ē“═Ļ│╔╚╬䚯╗
Ī±į┌ą┼Žó▓╗═Ļ╔ŲŻ©╔§ų┴╚▒Ę”ą┼ŽóŻ®Ą─ŪķørŽ┬ę└╚╗─▄ē“═Ļ│╔╚╬䚯╗
Ī±─▄ē“╠Ä└ĒĘŪ┤_Č©ąįĄ─╚╬䚯╗
Ī±─▄ē“╠Ä└ĒäėæB╚╬䚯╗
Ī±─▄ē“╠Ä└ĒČÓŅIė“║═ČÓ╚╬äšĪŻ
¼Fį┌Ą─╚╦╣żųŪ─▄ū÷Ą─▓ó▓╗╩Ūšµš²Ą─ųŪ─▄ĪŻ╦³╩Ū▀xō±┴╦─Ūą®┤_Č©ąįĄ─ĪóņoæBĄ─å¢Ņ}Ż¼▀@éĆ▒ŠüĒŠ═╩Ūėŗ╦ŃÖCĢ■Ė╔Ą─╩┬ĪŻėŗ╦ŃÖC▓╗Ģ■Ė╔Ą─╩┬╩ŪļSÖCæ¬ūāŻ¼┼eę╗Ę┤╚²Ż¼ė╔▒Ē╝░└’Ż¼▀@▓┼╩ŪųŪ─▄Ą─▒Š┘|ĪŻ╬ęéā▀^╚źū÷Ą─ŽĄĮyŻ¼ø]Ę©ū÷ĄĮųŪ─▄Ą─▒Š┘|Ż¼ę“×ķ╬ęéā▀Ć▓╗ų¬Ą└ĪŻ╔ŅČ╚īW┴ĢĮo┴╦╬ęéāę╗éĆ╠ß╩ŠŻ¼Š═╩Ū╬ęéāęčĮøĮėė|ĄĮ┴╦ųŪ─▄Ą─▒Š┘|ĪŻ─Ū├┤╬ęéāčžų°▀@éĆ╚źū÷Ż¼▓┼ėąŽŻ═¹ĪŻ
┤¾╝ę¼Fį┌Č╝į┌Ž¹┘M╔ŅČ╚īW┴ĢĪŻ╬ęéāČ╝ų¬Ą└Ż¼╚ń╣¹ė├╔ŅČ╚īW┴ĢüĒū÷ūRäeŻ¼░č╩»Ņ^┐┤│╔╚╦ø]ėąĻPŽĄŻ╗Ą½╩Ūū÷øQ▓▀Ż¼░čö│╚╦┐┤│╔┼¾ėč╩Ū▓╗į╩įSĄ─ĪŻ╔ŅČ╚īW┴Ģ▓╗ĮŌøQ▀@éĆå¢Ņ}Ż¼╦³Į^ī”Ģ■«a╔·┤¾ÕeĪŻ▀@╩Ū╦³▒Š┘|įņ│╔Ą─ĪŻ ╦∙ęį╬ęę╗ų▒šfŻ¼ĄĮ─┐Ū░×ķų╣Ż¼į┌Å═ļs┬ĘørŽ┬Ż¼▀Ć║▄ļyīŹ¼Fšµš²Ą─¤o╚╦▄ćŻ¼ĪĖ¤o╚╦▄ćĪ╣┼į▀ģ▀ĆąĶę¬ū°ę╗éĆ╚╦ĪŻ×ķ╩▓├┤Ż┐╔į╬óČ«³c╚╦╣żųŪ─▄Ą─╚╦Č╝ų¬Ą└Ż¼─┐Ū░╚╦╣żųŪ─▄▀Ć▓╗─▄ĮŌøQ═╗░l╩┬╝■ĪŻ
▀^╚ź╬ęéāø]ėą─▄┴”ū÷ĄĮšµš²ųŪ─▄▀@ę╗³cĪŻČ°Į±╠ņ╩Ū┐ŲīW蹊┐╚╦åTĄ─ę╗éĆÖCĢ■ĪŻŽŻ═¹┤¾╝ę╚źū÷ĪŻ╚ń╣¹┤¾╝ę│ų└m╚źū÷Ż¼╬ęŽÓą┼Ģ■ėąą┬Ą─░l¼FĪŻ¼Fį┌║▄ČÓ╚╦┐┤ĄĮ┴╦╔╠ÖCŻ¼┐┤ĄĮ┴╦æ¬ė├Ż¼┐┤ĄĮ┴╦ėŗ╦ŃÖC┤“öĪ└Ņ╩└╩»Ż¼Ą½ģs║▄╔┘╚╦ėą┐┤ĄĮ▀@ę╗³cĪŻŠų═Ō╚╦┐┤▓╗ŪÕŻ¼ū„×ķŠųā╚╚╦Ż¼╬ę╠ßąč┤¾╝ęŻ¼Į╠╩┌欫ö┐┤ĄĮĪ¬Ī¬AI ┐ŲīWĄ─╩’╣ŌĪŻ
